本文共 4038 字,大约阅读时间需要 13 分钟。
mysql自带分表分区策略
mysql 自带有分区分表策略、具体参考。只能说单库情况下、并且简单的情况如按时间做range分区可以使用mysql自带分区策略。更多的情况下完全要自己代码逻辑实现。
开源解决方案
开源中间件或框架
- cobar
- TDDL
- atlas
- sharding-jdbc 当当开源产品,属于client方案
- mycat 基于cobar改造,属于proxy方案
sharding-jdbc和mycat使用不同的理念,sharding-jdbc目前是基于jdbc驱动,无需额外的proxy,因此也无需关注proxy本身的高可用。Mycat 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库,而 Sharding-JDBC 是基于 JDBC 接口的扩展,是以 jar 包的形式提供轻量级服务的。
解决方案
- Proxy 代理模式
- Client 客户端模式
Proxy 代理模式
应用程序和数据库 中间,单独部署一个代理层中间件,所有的连接和数据库操作都发给这个代理层,由代理层去做底层的实现。
(1)事先在代理中间件上配置分片规则、
(2)代理中间件拦截客户端sql、并对sql解析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库
(3)并将返回的结果做适当的处理,最终再返回给用户。
(4)对返回结果进行合并等相关处理处理、并返回给客户端。
这样做对开发人员来说,是完全不需要知道下面做了什么的,甚至不需要做任何的代码改造,就可以完成接入;
常见的框架有:MyCat(支持 MySQL, Oracle, DB2, PostgreSQL, SQL Server等主流数据库,基于Cobar改造的)、Cobar(阿里,已停止维护)、MySQL-Proxy、Atlas(360开源的)、sharing-sphere(当当)等等。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kAdsGpSk-1603200537142)(C:\Users\mocar\AppData\Local\Temp\1602429967750.png)]](https://img-blog.csdnimg.cn/20201020214135992.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1NldmVuNzExMTE=,size_16,color_FFFFFF,t_70#pic_center)
Client 客户端模式
在客户端做路由分发等相关操作、如sharding-jdbc,是一个jar包、应用程序集成此jar包开发即可。
关于分库分表算法的实现
此处列举几个常用的算法
范围分区
如按照时间2020-10到2020-11月在一个表、按照金额100<x<1000在一个表。
- 优点
此方法可以方便动态扩容、不需要迁移数据、不需要重启db服务。
- 缺点
容易产生热点问题、如某个月数据量特别大
hash 分区
对id的hash取模x。网上搜很多例子
- 优点
事先确定表数量n、直接x%n得到表的下标,对一开始需要分配很多表的比较方便
- 缺点
hash分布不均匀(如果id不是自增整形、hash函数影响河大)、会导致表的负载不均匀
无法指定某个id到某个表
后期动态扩容麻烦、需要重新计算hash、并迁移数据库、迁移过程可能需要停止爱数据库服务。
一般hash
如果增加表、则原来所有表都要重新计算并迁移数据。
一致性hash
如果只新增n个表、则最多只需要迁移原来的n个表、最少只需要迁移原来的1个表。
自定义key或特殊标识
请参考下一章节
分库分表-自定义key或特殊标识
即插入时、就固定此 记录 所在哪个表中、此种方式不在需要重启或者暂停数据库、不影响应用。
还是回到分片key问题上,要解决热点写入问题,最终还是要处理,如何尽可能均衡的写入到数据库,缓解热点压力,所以还是要从分片key生成策略上入手。既然使用精确分片算法(PreciseShardingAlgorithm),那就准确的控制数据最终会落到哪一个库哪一个表。分片key设计如下:
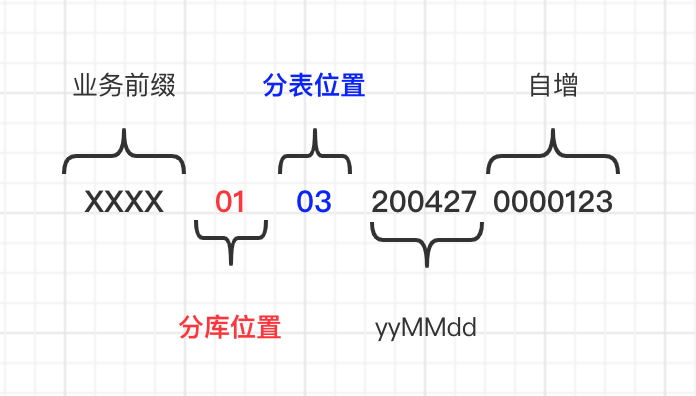
为何扩容不需迁移
因为新增数据时已经在记录的key上固定了数据库表的的编号。
为何不需暂停数据库
因为不需要迁移
为何不需暂停应用服务
扩充数据库表时、用用端只需要修改原来的key生成算法即可。
分布式应用下key生成算法
利用redis 存储列表+lua原子原子操作。
数据分配不均衡
按照以上的逻辑,是解决了数据库扩容的问题。但是出现了一个新的问题,继续往复的生成分片key,数据还是分散的到每个库每个表,我们之所以要增加数据库扩容,是因为原有的数据库表数据量已经到了计划扩容的临界值,我们才进行扩容。这时候我们希望降低原有数据库的数据写入权重。这里我的想法是根据各库表的容量做一个分片key生成的动态权重调整,出发点是定时任务统计每个库的每个表数据量来进行调整。
总的来说:如何确定key的库表编号 或者说 如何确定数据应该到哪个表或者库呢,我们根创建据数据库表时预估容量 和 当前使用容量,来控制插入某个数据库表的概率或者权重、具体实现请看下面章节。
生成key-基于库表编号的列表随机
假如现在表A在库中分了两个表、编号分别是0101,0102 他们预估容量是1:1、下面我们要做基于权重生成key。
- 根据表预估容量大小比为1:2、所以我们 初始化库表编号DTL列表[0101,0102,0102]
- 每次生成key随机从列表中取一个数
- 定时或者手动查询表的容量、动态调整权重。如此时发现两表的已用容量为2:1,则此时两表的剩余容量变为1:4 则要调整DTL=[0101,0102,0102,0102,0102] ,是为了让更多的数据进入到0102来保持平衡
- 当扩容时增加表时、同样要考虑到 预估容量与亿使用容量 进行初始化DTL列表。防止数据分配不均衡。
生成key-基于库表编号的环轮询
此章节转自 https://juejin.im/post/6844904142578647053
我们计划单个表的数据量为300万(可以根据数据库服务器性能评估表的数据量上限),当表数据量超过计划阈值,我们开始降低表的写入权重,
- 第一档阈值60%(180万),降低表数据写入权重
- 第二档阈值70%(210万),再次降低写入阈值,评估所有库和表的数据量,开始进行数据库扩容
- 第三档阈值85%(255万),不再写入数据,这里的不再写入数据并不是绝对的,是计划预留一定的数据空间容错,最好能监控到达该阈值还有写入数据,做一个报警,及时调整分片key生成策略,避免数据超出计划的最高值。
初始化
计划定了三档阈值,我们就初始化三个写入权重,生成好以后放入环形结构的数组。

某一个表达到阈值
任务统计结束后,01库的01表达到第一档阈值,重新初始化数据环的时候,移除一个权重,到达第二档再移除一个权重。
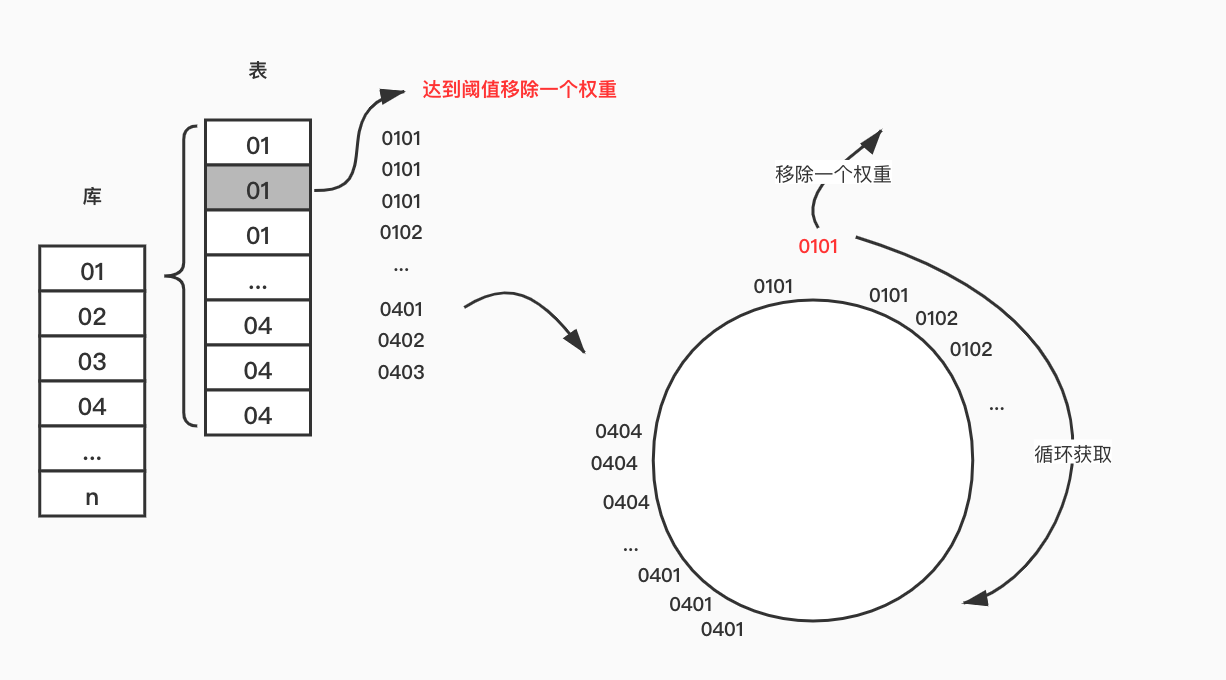
某一个表不再写入数据
当某个表数据量到达第三档,不再写入数据,重新初始化环,移除这个表的写入权重。

扩容新增数据库
增加数据库后,我们需要重新初始化环,需要确认新增数据写入扩容新增的数据库中,可以考虑手动触发重新初始化,如果任务时间间隔不长,也可以等待任务初始化,只需要注意任务执行后有数据写入新库即可。
权重调整策略
前面提到的权重调整,判断依据是表的数据量是否达到阈值,注意是分库分表的每个库里的每个表单独统计是否达到阈值进行调整,采用定时任务的方式执行,间隔频率可以根据数据增长量评估。
基于自定义key方案的局限性
这个方案虽然很好的解决了扩展增加数据库的问题,但是也有一些使用的局限,首先,依赖于数据分片key的生成,很难再已有数据的基础上使用这个方案(接受新的数据关联key有不小的调整成本)。其次,数据分片位生成策略也有一定的复杂度,这里不再深入,方案其实很多,借助于zk或者redis等三方工具可以搭建一个序号生成服务,既能保证一定的效率,也能保证序号的唯一性。
如果是新的业务线,在数据增量上无法预估未来一两年的数据量,考虑使用分库分表,不妨可以考虑这个方案,减少增加库和表带来的痛苦。以后有足够的运维能力支撑TiDB,分库分表带来的诟病才能一扫而光,最终还是单表操作来的香,啥也不多想,上去就干(TiDB也有不少坑等着踩)!
不同MySQL实例下的跨库
业务场景:关联不同数据库中的表的查询
比如说,要关联的表是:机器A上的数据库A中的表A && 机器B上的数据库B中的表B。
这种情况下,想执行“select A.id,B.id from A left join B on ~~~;“那是不可能的,但业务需求不可变,数据库设计不可变,这就蛋疼了。。
解决方案:在机器A上的数据库A中建一个表B。。。
这当然不是跟你开玩笑啦,我们采用的是基于的federated引擎的建表方式。
建表语句示例:CREATE TABLE `table_name`(......) ENGINE =FEDERATED CONNECTION='mysql://[username]:[password]@[location]:[port]/[db-name]/[table-name]'
前提条件:你的mysql得支持federated引擎(执行show engines;可以看到是否支持)。

如果有FEDERATED引擎,但Support是NO,说明你的mysql安装了这个引擎,但没启用,去my.cnf文件末添加一行 federated ,重启mysql即可;
如果压根就没有FEDERATED这一行,说明你的mysql就没有安装这个引擎,这就不能愉快的玩耍了,最好去找你们家运维搞定吧,因为接下来的动作比较大,而且我也不知道怎么搞;
解释:通过FEDERATED引擎创建的表只是在本地有表定义文件,数据文件则存在于远程数据库中,通过这个引擎可以实现类似Oracle 下DBLINK的远程数据访问功能。就是说,这种建表方式只会在数据库A中创建一个表B的表结构文件,表的索引、数据等文件还是在机器B上的数据库B中,相当于只是在数据库A中创建了表B的一个快捷方式。
需要注意的几点:
1. 本地的表结构必须与远程的完全一样。
2.远程数据库目前仅限MySQL
3.不支持事务
4.不支持表结构修改
转载地址:http://hmyvf.baihongyu.com/